- Dimensional modeling is one of the most popular data modeling techniques for building a modern data warehouse. It allows customers to quickly develop facts and dimensions based on business needs for an enterprise.
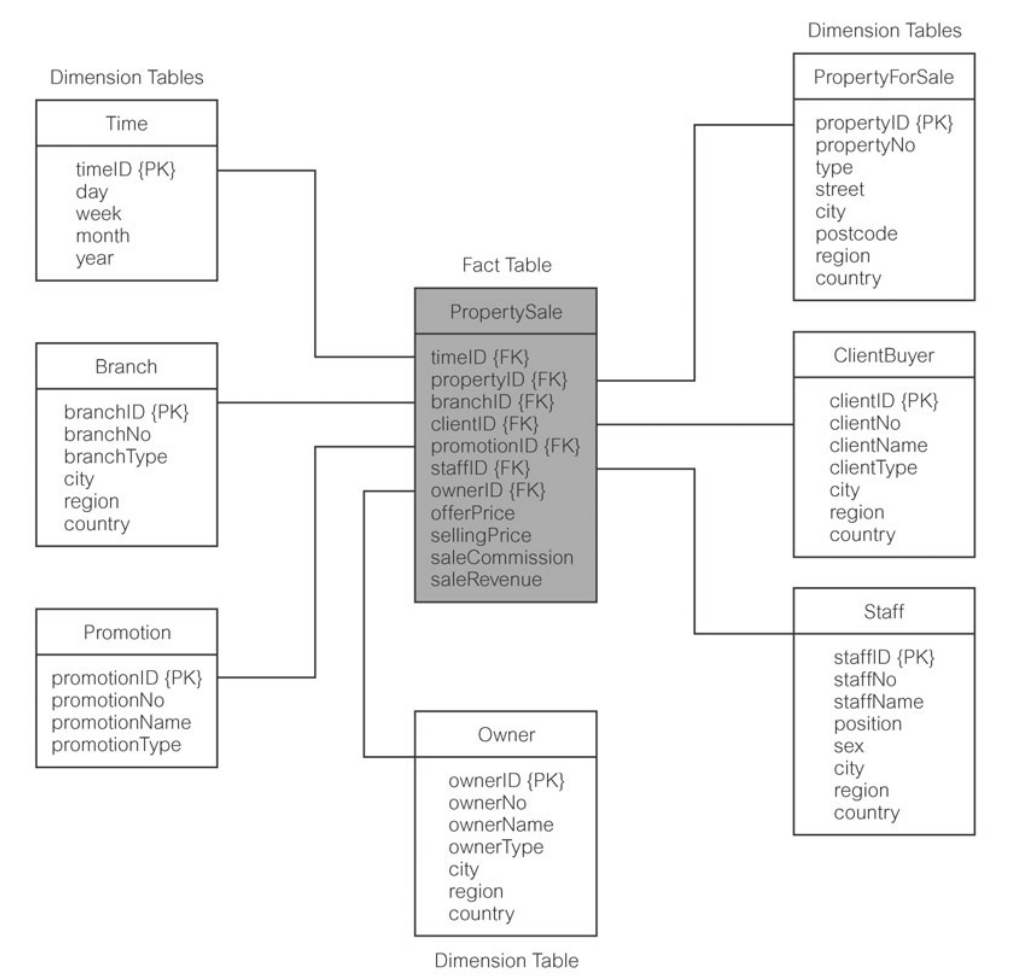
- Every dimensional model is composed of one table with a composite primary key, called fact table, and a set of smaller tables, called dimension tables.
- The PK of the fact table is made up of two or more foreign keys.
- Generally, another name for the dimensional model is the star schema.
- It is important to treat fact data as read-only data that will not change over time.
- The most useful fact tables contain one or more numerical measures that occur for each record (numerical and additive — eg. offerPrice, SellingPrice, saleCommission, saleRevenue)
Star Schema: Dimensional data model, that has a fact table in the centre, surrounded by denormalized dimension tables.
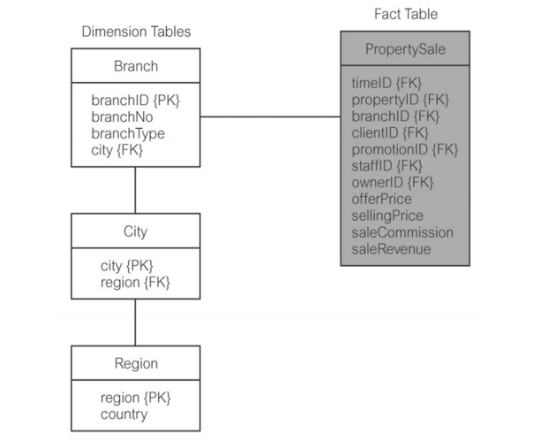
Snowflake Schema: Dimensional data model, that has a fact table in the center, surrounded by normalized dimension tables.
Important Features of Dimensional Model:
- All natural keys are replaced with surrogate keys. e.g every join between fact and dimension tables is based on surrogate keys, not natural keys.
- (eg. Each each branch has a natural key, branchNo, and also a surrogate key namely branchID)
- In dimensional modeling, surrogate keys are often used instead of natural keys for several reasons:
Benefits of Using Surrogate Keys:
- Stability of Surrogate Keys:
- Natural keys, such as business keys or composite keys from the source system, may change over time due to business reasons (e.g., mergers, acquisitions, reorganizations).
- Surrogate keys are system-generated and have no business meaning, making them stable and less prone to changes. This stability is crucial for maintaining historical data integrity in a data warehouse.
- Performance:
- Surrogate keys are typically integers and are often smaller in size compared to composite natural keys, which can be longer alphanumeric strings.
- Smaller keys contribute to better performance in terms of storage space, indexing, and query processing.
- Simplifies Joins:
- Natural keys may have complex structures or hierarchies that make joining tables more cumbersome.
- Surrogate keys simplify joins as they are simple integers, improving query performance and readability.
- Consistent Length:
- Surrogate keys usually have a consistent length, making it easier to work with and manage index structures.
- Natural keys may have varying lengths, which can complicate index management and impact performance.
- Enhanced Security:
- Surrogate keys help enhance security by abstracting the underlying business data. Users querying the data warehouse may not need to see or understand the actual business keys.
- Easier to Manage Changes:
- If there are changes in the source system’s structure or keys, using surrogate keys allows for easier adaptation without affecting the data warehouse schema or historical data.
- Facilitates Integration:
- Surrogate keys can simplify the integration of data from multiple source systems with different key structures. This flexibility is particularly useful in a data warehouse environment.
Difference between Star and Snowflake Schema
Star schemas are optimized for reads and are widely used for designing data marts, whereas snowflake schemas are optimized for writes and are widely used for transactional data warehousing. A star schema is a special case of a snowflake schema in which all hierarchical dimensions have been denormalized, or flattened.
| Attribute | Star schema | Snowflake schema |
|---|---|---|
| Read speed | Fast | Moderate |
| Write speed | Moderate | Fast |
| Storage space | Moderate to high | Low to moderate |
| Data integrity risk | Low to moderate | Low |
| Query complexity | Simple to moderate | Moderate to complex |
| Schema complexity | Simple to moderate | Moderate to complex |
| Dimension hierarchies | Denormalized single tables | Normalized over multiple tables |
| Joins per dimension hierarchy | One | One per level |
| Ideal use | OLAP systems, Data Marts | OLTP systems |
Table: A comparison of star and snowflake schema attributes.Comparing benefits: snowflake vs. star data warehouses
The snowflake, being completely normalized, offers the least redundancy and the smallest storage footprint. If the data ever changes, this minimal redundancy means the snowflaked data needs to be changed in fewer places than would be required for a star schema. In other words, writes are faster, and changes are easier to implement.
However, due to the additional joins required in querying the data, the snowflake design can have an adverse impact on read speeds. By denormalizing to a star schema, you can boost your query efficiency.
You can also choose a middle path in designing your data warehouse. You could opt for a partially normalized schema. You could deploy a snowflake schema as your basis and create views or even materialized views of denormalized data. You could for example simulate a star schema on top of a snowflake schema. At the cost of some additional complexity, you can select from the best of both worlds to craft an optimal solution to meet your requirements.
Practical differences
Most queries you apply to the dataset, regardless of your schema choice, go through the fact table. Your fact table serves as a portal to your dimension tables.
The main practical difference between star and snowflake schema from the perspective of an analyst has to do with querying the data. You need more joins for a snowflake schema to gain access to the deeper levels of the hierarchical dimensions, which can reduce query performance over a star schema. Thus, data analysts and data scientists tend to prefer the simpler star schema.
Snowflake schemas are generally good for designing data warehouses and in particular, transaction processing systems, while star schemas are better for serving data marts, or data warehouses that have simple fact-dimension relationships. For example, suppose you have point-of-sale records accumulating in an Online Transaction Processing System (OLTP) which are copied as a daily batch ETL process to one or more Online Analytics Processing (OLAP) systems where subsequent analysis of large volumes of historical data is carried out. The OLTP source might use a snowflake schema to optimize performance for frequent writes, while the OLAP system uses a star schema to optimize for frequent reads. The ETL pipeline that moves the data between systems includes a denormalization step which collapses each hierarchy of dimension tables into a unified parent dimension table.
Resources:
https://www.ibm.com/docs/en/informix-servers/14.10?topic=model-concepts-dimensional-data-modeling
https://www.it.kmitl.ac.th/~pattarachai/DB/class/31DWDesign.pdf
Discover more from Data Engineer Journey
Subscribe to get the latest posts sent to your email.