What is Wide-Facts, why we need it?
“Wide-Fact” is a fact table that contains a high number of columns and is relatively wide, often due to the inclusion of many measures or attributes related to a specific business process. This design choice can make querying and reporting more convenient since it contains various measures in a single table. In addition, the benefit is you can create keys and indexes and speed up reporting. For example, it is not convenient and easy to create and use indexes in reporting side (e.g. Tableau/ Power BI), but you can create easily in ETL development process (e.g. using Pentaho/Talend). However, the wide-fact table can potentially impact performance and storage requirements.
So, why bother with Wide Facts?
- Awesome Analytics: When your data game is on another level.
- Report like a Pro: One-stop-shop for all your measures, making reporting easy.
- Tailored to You: Specific business needs? Wide-Facts got you covered.
Generally, for reporting purpose, it is best practice to develop a wide-fact table, but the decision to use a wide-fact table in a data warehouse depends on company’s specific needs, the nature of the data, and the intended use cases.
Designing Wide-Facts
Wide-Fact table, with many attributes, is a part of a star schema. In a typical star schema, tables are often denormalized for performance, reducing the need for joins during metric queries. However, dimension tables remain normalized to ensure data consistency, minimize redundancy, and maintain clear descriptive attributes.
To demonstrate, we are joining two simple tables (but real wide-facts will have many attributes)
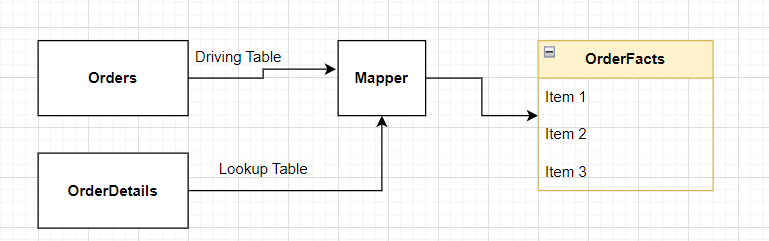
What we have? Orders and OrderDetails table
What we want to create? OrderFacts (by combining Order and OrderDetails)
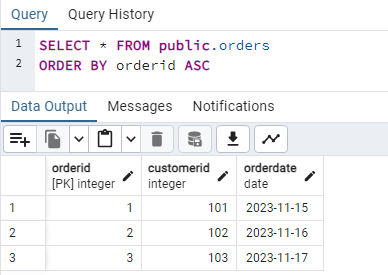
Orders Table
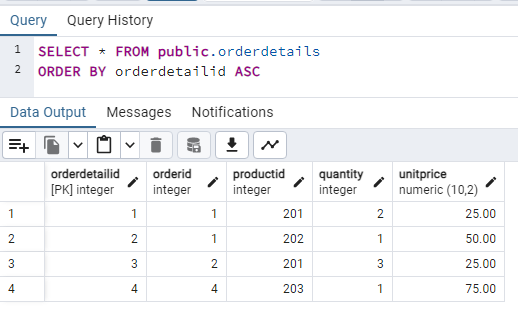
OrderDetails Table
In real ETL development process, we use mapper (e.g. in tMap in Talend), but for simplicity, I am showing using SQL as following:
SELECT Orders.OrderID, Orders.CustomerID, Orders.OrderDate, OrderDetails.OrderDetailID, OrderDetails.ProductID, OrderDetails.Quantity, OrderDetails.UnitPrice
FROM Orders
LEFT JOIN OrderDetails ON Orders.OrderID = OrderDetails.OrderID;Showing the output in PgAdmin:
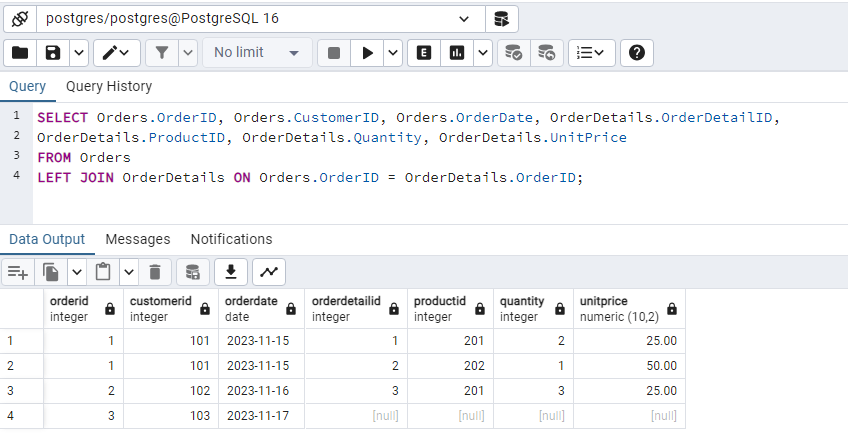
What’s wrong here? Consequences of Orphan Records
This wide-fact table is incomplete because a particular record is missing (record with orderid =4); this happened because the record was orphaned, a consequence of a lack of referential integrity in the database.

So, this example clearly shows why we should not neglect referential integrity when designing database.
How Orphan Records impact in Data Warehouse?
- Inaccuracy in Analysis: Orphan records can lead to incomplete or inaccurate analysis as the related data might be missing, affecting insights and decision-making based on incomplete iformation.
- Data Integrity Concerns: Orphan records can create data integrity issues and challenges in maintaining a consistent view of information across the warehouse.
- Reporting Challenges: When generating reports or conducting analysis, orphan records might lead to unexpected gaps or inconsistencies in the data, impacting the reliability of reports.
- Query Performance Issues: If not handled properly, orphan records might affect query performance, especially in complex queries that involve joins between fact and dimension tables.
Efficient management of orphan records, through data cleansing, integrity checks, and referential integrity constraints, is crucial for a healthy and accurate data warehouse environment.
Preventing Orphan Records: Strategies for the Future
While controlling or redesigning the company’s ERP system might be beyond your scope, certain strategies can prevent orphan records in the future:
- Referential Integrity Constraints: Enforce these constraints in the database schema to prevent the creation of orphan records.
- Data Validation and Cleansing: Regularly validate and cleanse data to identify and rectify orphan records.
- ETL Processes: Include validation steps in ETL processes to prevent the insertion of records with non-existent keys.
- Surrogate Keys: Use surrogate keys in dimension tables to establish relationships with fact tables, minimizing the chances of creating orphan records.
- Regular Audits and Monitoring: Conduct routine audits and monitoring to detect and address orphan records.
- Error Handling and Logging: Implement robust error handling to capture instances where data integrity constraints are violated, allowing for tracking and resolution.
By implementing these strategies, organizations can effectively mitigate the occurrence of orphan records in their data warehouse, ensuring data accuracy, reliability, and consistency for analytics and decision-making.
Discover more from Data Engineer Journey
Subscribe to get the latest posts sent to your email.