
As you transition from a Talend background to the world of Azure Data Engineering, understanding how familiar data integration concepts map to Azure Data Factory (ADF) components is a crucial step. ADF is Microsoft’s cloud-based ETL/ELT service, designed for scaling data movement and transformation in the cloud. While the fundamental goals of moving and transforming data remain the same, the architecture and terminology differ. This comparison highlights the core ADF building blocks and their closest counterparts in the Talend ecosystem you’re already comfortable with, using a lovely shade of green along the way!
1. Workflow Orchestration
Azure Data Factory: Pipeline
Description: A logical grouping of Activities that defines a complete workflow for data integration or transformation.
Role: It’s your canvas where you define the sequence of steps ADF should execute, including data movement, transformation, and control flow logic.
Example:
Imagine a Pipeline named LoadDailySales. This pipeline might contain a Copy Data activity to pull data from a source, followed by a Data Flow activity to clean and aggregate that data, and finally a Stored Procedure activity to load it into a data warehouse table. The dependencies between these activities (e.g., run Data Flow only On Success of Copy) define the flow.
Concept: Think of it as the overall job stream or the main job itself in Talend terms, but built from distinct, orchestrated cloud service calls (Activities).
Talend: Job
Description: The fundamental executable unit in Talend Studio. It’s a graphical workspace where you drag-and-drop components and connect them.
Role: Defines the data flow and process logic. You visually design the steps, transformations, and error handling using components and links.
Example:
A Talend Job named ETL_SalesData would involve placing components like tFileInputDelimited (to read the CSV), tMap (to perform transformations), and tDBOutput (to load into the database). You connect these components with Row links (Main, Lookup, Reject) and Trigger links (On Component Ok, On Component Error).
Concept: This is where you build the specific data processing logic directly using Talend’s component library.
Key Distinction
While both represent workflows, an ADF Pipeline is primarily an *orchestrator* that tells other Azure services (via Activities) what to do. A Talend Job *is* the execution unit that directly contains the data processing logic built from its internal components.
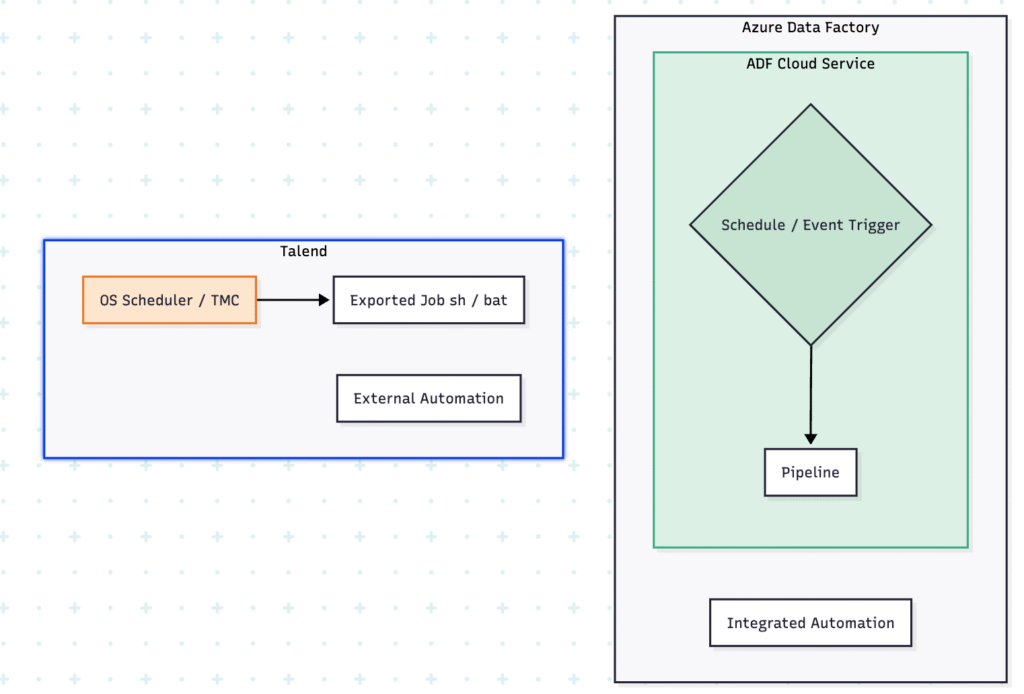
2. Execution Timing & Automation
Azure Data Factory: Trigger
Description: A core ADF component that specifies when a Pipeline execution should start. It’s explicitly linked to one or more pipelines.
Role: Automates pipeline execution. You don’t need external schedulers; ADF handles this natively.
Types:
Schedule Trigger: Runs on a fixed schedule (e.g., daily, hourly).Tumbling Window Trigger: Runs on a periodic interval over discrete, non-overlapping time windows.Event Trigger: Responds to events like a file being created or deleted in cloud storage (Blob Storage, ADLS Gen2).
Example:
Creating a Schedule Trigger and setting its recurrence to run the LoadDailySales pipeline every morning at 5 AM UTC. Or, creating an Event Trigger to kick off a pipeline whenever a new sales file arrives in an input folder.
Concept: Your built-in alarm clock or event listener for pipelines.
Talend: Scheduler (OS or TMC)
Description: Execution scheduling is often managed by external systems or within Talend’s enterprise management layer.
Role: To invoke compiled Talend Jobs at specific times or intervals.
Mechanisms:
- Operating System Schedulers (
cronon Linux, Task Scheduler on Windows): Compile the Talend Job into an executable script and schedule that script. - Talend Management Console (TMC): Provides a web-based interface to schedule jobs deployed to the Talend Runtime.
- Event-based triggering often requires polling logic *within* the Talend Job or using external tools.
Example:
Exporting the ETL_SalesData Job as a shell script and setting up a cron entry on a server: 0 5 * * * /path/to/my/job/run_ETL_SalesData.sh. Or, configuring a daily schedule for the deployed job in TMC.
Concept: Your external alarm clock or job launcher that points to the Talend executable.
Key Distinction
ADF’s Triggers are native, cloud-integrated objects within the ADF service, tightly integrated with pipelines and supporting cloud-native event triggers. Talend relies more heavily on external OS schedulers or its separate management console (TMC) for automation.
3. Handling Execution Outcomes
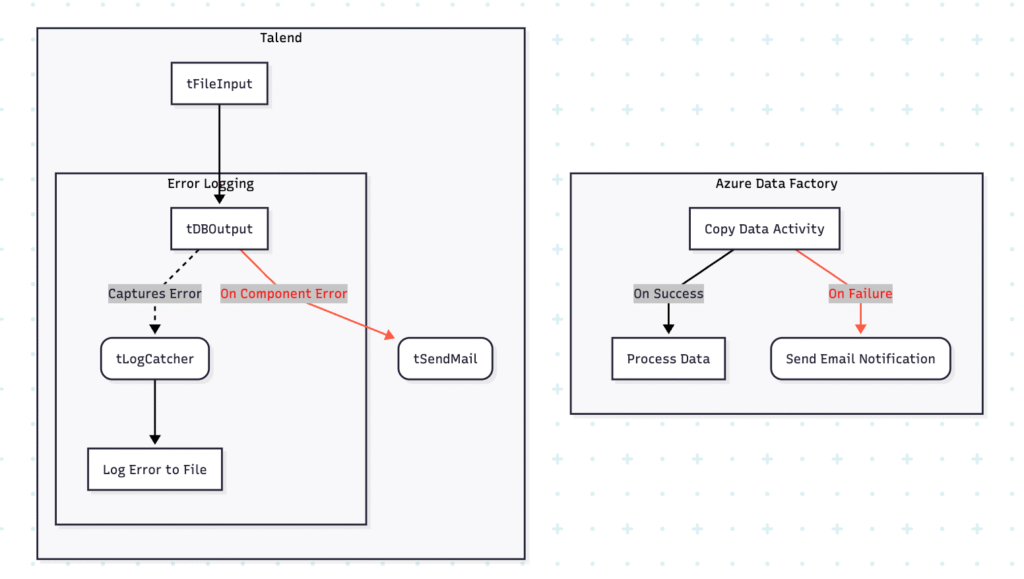
Azure Data Factory: Error Handling
Mechanism: Defined using dependency settings between Activities within a Pipeline.
Role: To control the workflow flow based on whether an upstream activity succeeds, fails, or completes.
Dependencies: Activities are linked with conditions:
- Green (Success): Run next activity only if previous succeeds.
- Red (Failure): Run next activity only if previous fails.
- Blue (Completion): Run next activity regardless of success or failure.
Example:
Adding a Web Activity to call a notification service and linking it to the Copy Data activity with a `On Failure` dependency. If the copy fails, the email notification activity runs. Use the ADF monitoring UI or Azure Monitor logs to diagnose failures.
Concept: Branching logic based on the exit status of each step in the pipeline.
Talend: Error Handling (Trigger Links, Components)
Mechanism: Implemented using specific “Trigger” links between components and dedicated error-related components.
Role: To define alternative execution paths and capture/process error information when a component fails.
Links/Components:
On Component Ok(Green): Executes next component if previous completes successfully.On Component Error(Red Lightning Bolt): Executes next component only if previous fails.tLogCatcher: Captures Java exceptions, `tDie` messages, and `tWarn` messages from other components.
Example:
Connecting a tSendMail component to your tDBOutput component with an On Component Error link. Add a tLogCatcher linked to a tLogRow or tFileOutputDelimited to log error details within the job flow.
Concept: Explicitly designing alternative routes and using specific components to handle errors encountered by individual processing units.
Key Distinction
Both use graphical means to define error flow. ADF primarily uses dependency conditions on links between activities. Talend uses specific error-type trigger links and dedicated components (`tLogCatcher`, etc.) within the job design to route execution and manage error data.
4. Connecting to External Systems
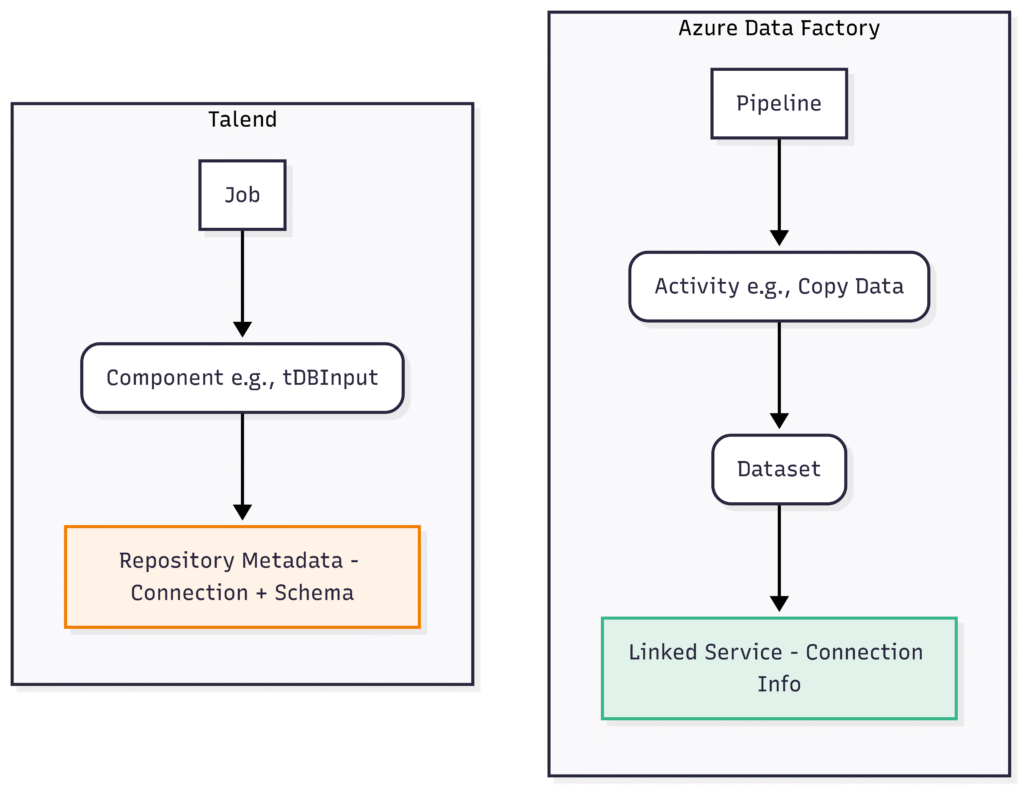
Azure Data Factory: Linked Service
Description: Defines the connection information required for ADF to connect to an external resource (data store or compute).
Role: Securely stores connection strings, credentials, endpoint URLs, and authentication methods. Acts as a bridge between ADF and external systems.
Key Aspect: Reusable across multiple Datasets and Activities within a Data Factory. Separates connection details from data definition (Dataset) and processing logic (Activity).
Example:
Creating a Linked Service for your Azure SQL Database (e.g., MySqlServerLS) which holds the server name, database name, and login credentials. Creating another Linked Service for your Azure Blob Storage (e.g., MyBlobStorageLS) with the account key or SAS token. These are then referenced by Datasets or Activities needing to access those resources.
Concept: Your centralized, secure vault for “how to connect” information for all external systems ADF needs to interact with.
Talend: Repository Connections / Metadata
Description: The Talend Repository stores reusable metadata about data sources, which includes connection details for databases, files, etc.
Role: Centralizes schema definitions and connection parameters so they can be reused across multiple Jobs and components without re-entering details.
Key Aspect: Metadata entries (like “DB Connections”, “File Delimited”, “Salesforce”) store both structural information (schema) and connectivity details. Components in a Job link to these repository entries.
Example:
Creating a “DB Connections” entry named ProductionDB in the Repository, configuring its type (e.g., SQL Server), host, port, database, user, and password. When adding a tDBOutput component to a Job, you select “Repository” for its settings and choose the ProductionDB entry. Similarly, you define “File Delimited” metadata for your CSV files.
Concept: Your design-time library for reusable data source definitions, including connection info and schema.
Key Distinction
Both provide reusable connection information. ADF Linked Services are specific to telling the *ADF service* how to authenticate and connect to external cloud/on-premises systems. Talend’s Repository Metadata stores connection *and schema* info for components *within* its jobs.
Transitioning technologies always involves a learning curve, but your experience with Talend provides a solid foundation. You’ve already mastered the core principles of data integration, workflow design, and connecting to various systems. Azure Data Factory builds upon these concepts but adapts them for the cloud-native environment. By understanding these parallels – Pipelines as your workflows, Triggers for automation, built-in error handling dependencies, and Linked Services for connections – you’re well-equipped to tackle the challenges and excel in your Azure Data Engineer journey.
Frequently Asked Questions for Talend Users
Q: What’s the equivalent of a Talend component (like tMap, tJoin, tAggregate) in ADF?
A: For data transformation, ADF offers Mapping Data Flows. These provide a visual, no-code/low-code way to design complex ETL/ELT transformations at scale. They run on Spark clusters managed by Azure Databricks or Azure Synapse Analytics. For simpler transformations or orchestrating code-based transformations, you’d use specific Activities like the Stored Procedure Activity (to run SQL), Databricks Notebook Activity (to run Python/Scala/SQL/R), Azure Function Activity, etc.
Q: Where do I define the structure (schema) of my source or target data in ADF?
A: This is defined using Datasets. A Dataset represents the structure and location of your data within a Linked Service. For example, a Dataset might define that data in the SalesBlobStorage Linked Service (the connection) is located in the `/input/sales/` folder and has columns like CustomerID, Amount, Date with specific data types. Datasets are then used by activities like Copy Data or Data Flow as the source or sink.
Q: How do I manage variables or parameters that change between environments (Dev, QA, Prod) in ADF?
A: ADF uses Parameters within Pipelines, Datasets, and Linked Services. These parameters can be set when a pipeline is triggered, allowing dynamic behavior. For managing secrets and sensitive environment-specific values (like passwords, connection strings), you integrate with Azure Key Vault, referencing secrets securely from Linked Services. During deployment across environments, you use Azure Resource Manager (ARM) templates (generated from your ADF code) to parameterize and deploy your ADF resources, including overriding Linked Service connection strings, parameter default values, etc., specific to the target environment.
Q: Is there a concept like Talend’s Context Variables in ADF?
A: Yes, Pipeline Parameters and Pipeline Variables serve a similar purpose to Context Variables within a Job. Pipeline Parameters are typically used for values passed into a pipeline when it runs (like file paths, dates, environment names – often set by the Trigger), allowing dynamic input. Pipeline Variables are used for temporary storage within the pipeline execution, similar to internal variables you might use in a Talend routine or component logic.
Q: How do I deploy my ADF pipelines and datasets from development to higher environments?
A: Deployment in ADF follows a DevOps approach. You typically integrate your ADF authoring with a Git repository (Azure Repos or GitHub). Changes committed to Git are then published. For automated deployment, you set up CI/CD pipelines (using Azure DevOps Pipelines or GitHub Actions) that automatically build (generate ARM templates from your ADF code) and release (deploy the ARM templates) your ADF resources to different environments (Dev, QA, Prod). ARM templates allow you to parameterize environment-specific settings.
Top Interview Questions (with a Talend Twist)
Be prepared to discuss these topics, potentially comparing and contrasting with your Talend experience:
- Explain the relationship between Pipelines, Activities, Datasets, and Linked Services in ADF.
- Describe the different types of Triggers in ADF and when you would use each. How does this compare to scheduling Talend Jobs?
- How would you handle parameters and variables in an ADF pipeline? How is this similar or different from Talend’s Context Variables?
- Explain how you would implement basic ETL transformations in ADF. (Mention
Copy Datafor simple mapping/schema changes, andMapping Data Flowsfor complex transformations running on Spark). - How do you secure credentials for data sources in ADF? (Mention Linked Services and integration with Azure Key Vault). How might this differ from how you managed credentials in Talend?
- Describe your approach to error handling and monitoring in ADF. How would you set up alerts for pipeline failures? Compare this process to your Talend error handling methods using Trigger links and components.
- What are Integration Runtimes in ADF and why are they important? (Discuss Azure IR, Self-Hosted IR, and Azure SSIS IR. This is somewhat analogous to where your Talend Job executes – local, remote server, cloud, vs. using a specific Integration Runtime compute provided by Azure).
- How do you deploy changes from development to production in ADF? (Discuss Git integration, CI/CD using Azure DevOps/GitHub, ARM templates).
- Imagine you need to copy data from an on-premises database to Azure Blob Storage. What ADF components and infrastructure would you use? (This specifically tests understanding of the Self-Hosted Integration Runtime).
- When would you choose to use ADF’s Copy Data activity versus a Mapping Data Flow? (Simple lift-and-shift vs. complex graphical transformation).
Visuals:
1. Workflow Orchestration (Pipeline vs. Job)

2. Automation (Trigger vs. Scheduler)
3. Error Handling
4. Connections (Linked Service vs. Repository)
Discover more from Data Engineer Journey
Subscribe to get the latest posts sent to your email.